[딥러닝초급] Overfitting and Underfitting
sources :
https://www.kaggle.com/code/ryanholbrook/overfitting-and-underfitting
Overfitting and Underfitting
Explore and run machine learning code with Kaggle Notebooks | Using data from DL Course Data
www.kaggle.com
Introduction
Recall from the example in the previous lesson that Keras will keep a history of the training and validation loss over the epochs that it is training the model. In this lesson, we're going to learn how to interpret these learning curves and how we can use them to guide model development. In particular, we'll examine at the learning curves for evidence of underfitting and overfitting and look at a couple of strategies for correcting it.
앞선 강의에서 손실함수를 이용하여 모델을 트레이닝하는 과정에 대해서 살펴보았다.
여기서는 학습곡선(Learning curve)에 대한 해석과 함께 어떻게 모델 개발을 이끌어 나갈 것인지 공부한다.
특히 학습곡선은 앞서 배운 Underfitting 과 Overfitting을 보여주는데, 이를 조정하기 위한 방법도 살펴보자.
Interpreting the Learning Curves
You might think about the information in the training data as being of two kinds: signal and noise. The signal is the part that generalizes, the part that can help our model make predictions from new data. The noise is that part that is only true of the training data; the noise is all of the random fluctuation that comes from data in the real-world or all of the incidental, non-informative patterns that can't actually help the model make predictions. The noise is the part might look useful but really isn't.
데이터가 모두 모델을 설명하기에 적합한 데이터가 되는 것은 아니다. 트레이닝 데이터로 입력된 데이터 중 일부는 노이즈가 껴 있는 경우가 있다. 이런 데이터 성격을 신호공학의 측면에서는 시그널과 노이즈로 구성된다고 설명한다. 시그널은 모델을 설명하고 예측하는데 도움을 주는 데이터라면 노이즈는 모델 외부 환경 영향으로 끼어든 무작위의 출렁임이며 어떠한 유의미한 정보를 전달하지 못하는 무작위의 신호 흐름이다. 당연히 노이즈는 모델을 설명하고 결과값을 예측하는데 도움이 되지 않는다.
We train a model by choosing weights or parameters that minimize the loss on a training set. You might know, however, that to accurately assess a model's performance, we need to evaluate it on a new set of data, the validation data. (You could see our lesson on model validation in Introduction to Machine Learning for a review.)
우리는 트레이닝 데이터의 손실함수를 최소화하는 가중치와 파라미터를 고르면서 모델을 트레이닝한다.
이 과정에서 한가지 알아야 할 것은 모델을 평가하려면 사실 우리는 트레이닝에 사용된 데이터 말고 새로운 데이터 셋을 가지고 평가해야 한다는 점이다. 이러한 데이터셋을 검증 데이터 셋(밸리데이션 데이터 셋; validation data set)이라고 한다.
When we train a model we've been plotting the loss on the training set epoch by epoch. To this we'll add a plot the validation data too. These plots we call the learning curves. To train deep learning models effectively, we need to be able to interpret them.
각 epoch 에포크 마다 트레이닝 데이터와 검증 데이터(밸리데이션 데이터 validation data)의 손실함수와 검증 데이터를 같이 그래프로 나타내는 것을 학습곡선(러닝 커브 Learning Curve)라고 부른다.
이 학습 곡선을 구성하고 해석한다면 딥러닝 모델을 효과적으로 학습시키는데 도움이 된다.
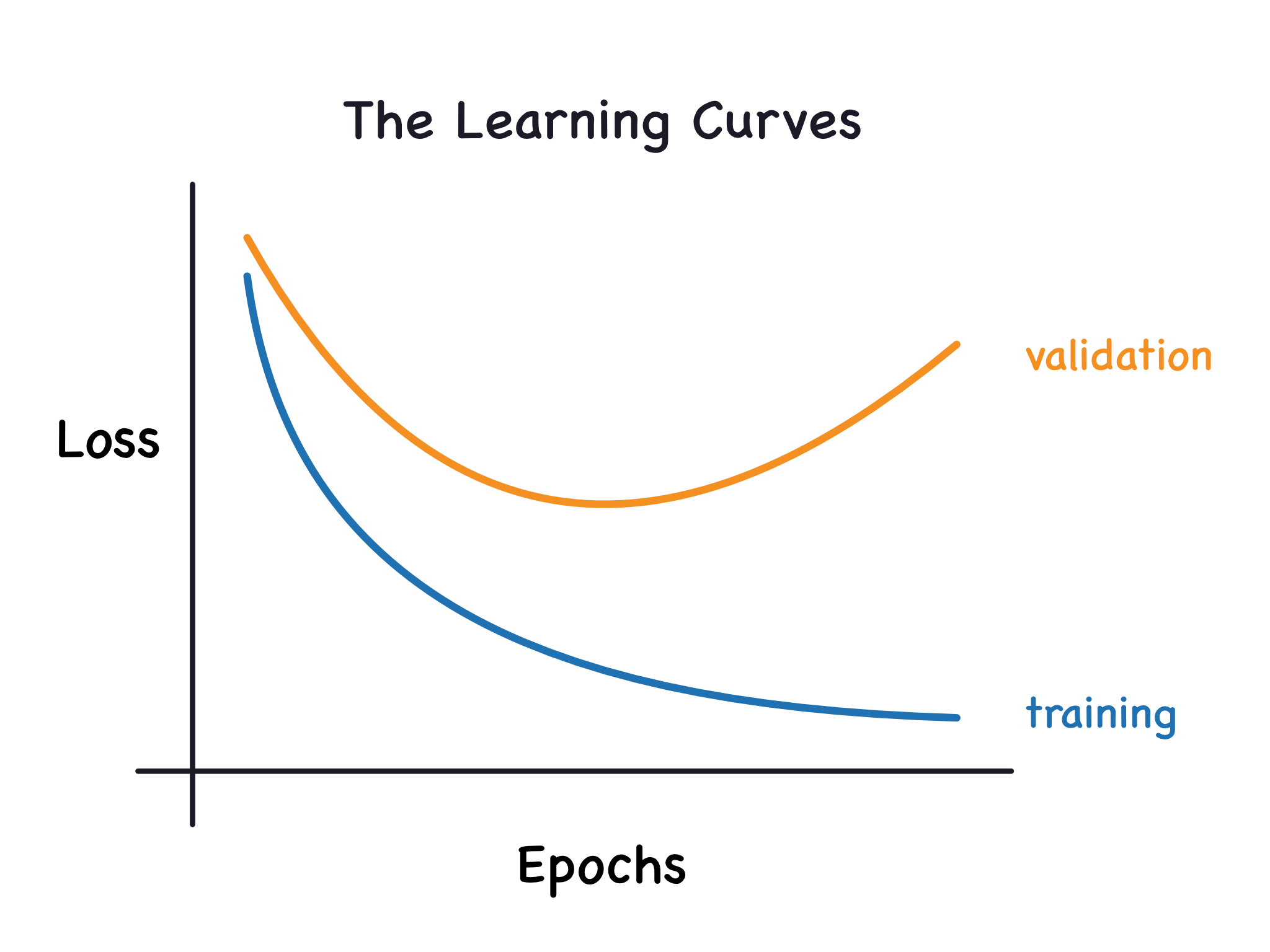
The validation loss gives an estimate of the expected error on unseen data.
(??? 뭔말이야.)
Now, the training loss will go down either when the model learns signal or when it learns noise. But the validation loss will go down only when the model learns signal. (Whatever noise the model learned from the training set won't generalize to new data.) So, when a model learns signal both curves go down, but when it learns noise a gap is created in the curves. The size of the gap tells you how much noise the model has learned.
트레이닝 데이터셋의 손실함수값(Loss function value)은 에포크를 거듭하면서 노이즈냐 시그널이냐에 상관없이 계속 하강한다.
그러나 밸리데이션 데이터셋의 손실함수값은 시그널을 배우고 있는 상황에서만 하강하고 노이즈를 배우고 있는 경우에는 상승하게 된다. 그래서 모델이 시그널로 이루어진 데이터셋을 학습하고 있다면 두개의 커브는 모두 하강하지만 노이즈를 배우고 있다면 두 커브의 차이(갭)가 벌어지게된다. 갭이 클수록 노이즈 입력이 많은 경우로 볼 수 있다.
Ideally, we would create models that learn all of the signal and none of the noise. This will practically never happen. Instead we make a trade. We can get the model to learn more signal at the cost of learning more noise. So long as the trade is in our favor, the validation loss will continue to decrease. After a certain point, however, the trade can turn against us, the cost exceeds the benefit, and the validation loss begins to rise.
이상적으로는 노이즈를 입력데이터에서 완전히 배제하는 것이 좋다. 그러나 이것은 실현되기 힘들다. 실제로 더 많은 데이터를 학습하기 위해서는 그만큼의 노이즈도 더 많이 들어오기 때문이다. 더많은 데이터를 위한 희생이 어느 정도 까지는 모델의 정확성을 높이는데 도움을 주지만 어느 시점부터는 오히려 해가 된다. 이러한 추세를 학습곡선이 보여주고 있다.
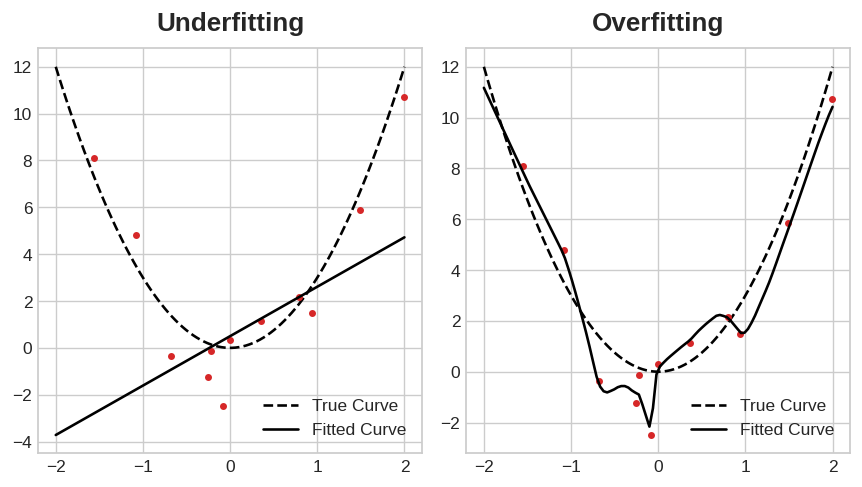
Underfitting and overfitting.
This trade-off indicates that there can be two problems that occur when training a model: not enough signal or too much noise.
자 앞서 더 많은 시그널을 받으려면 그만큼 노이즈도 많이 들어오게 된다는 이야기를 했다. 이러한 트레이드 오프 관계(노이즈는 안좋은데도 더 많은 시그널 때문에 받아들이는 관계를 맞교환했다고 표현) 모델을 트레이닝하는데 두가지 문제점을 내포한다.
충분하지 못한 시그널을 받는 문제와 너무 많은 노이즈를 받는 문제다.
Underfitting the training set is when the loss is not as low as it could be because the model hasn't learned enough signal. Overfitting the training set is when the loss is not as low as it could be because the model learned too much noise. The trick to training deep learning models is finding the best balance between the two.
언더피팅은 트레이닝 셋의 손실함수값이 충분히 작지 않은 경우 즉 모델이 충분한 시그널을 학습하지 못한 경우 발생한다. 오버피팅은 밸리데이션 셋의 손실값이 충분히 작지 않은 경우 즉 너무 많은 노이즈를 학습한 결과 발생한다. 딥러닝 모델을 잘 학습시키기 위한 방법중 하나는 이 둘 간의 밸런스가 필요하다고 앞서 배웠다.
#다소 비약이 있는 설명인듯 하지만. 그냥 넘어간다.
...
그러고는 갑자기 아래 노이즈 감소 대책을 논의했는데, 정리하자면
모델을 잘 피팅하려면 --> 많은 데이터를 학습해야 하는데,
데이터 = 시그널 + 노이즈 다.
데이터가 많아지면 노이즈도 많아진다.
데이터가 너무 작으면 시그널이 적으므로 언더피팅.
데이터가 너무 많으면 노이즈도 많으므로 오버피팅.
그럼
데이터는 많지만 노이즈를 줄이는 방법은 없는가?
그 이야기를 아래 하고 있다.
We'll look at a couple ways of getting more signal out of the training data while reducing the amount of noise.
따라서 우리는 어떻게 트레이닝 데이터셋에서 노이즈를 줄여나갈 수 있는지 몇가지 방법을 살펴보고자 한다.
Capacity
A model's capacity refers to the size and complexity of the patterns it is able to learn. For neural networks, this will largely be determined by how many neurons it has and how they are connected together. If it appears that your network is underfitting the data, you should try increasing its capacity.
모델의 캐퍼시티(capacity)는 그 모델이 배울 수 있는 패턴의 복잡도와 사이즈를 의미한다.
신경망에서는 뉴런의 수량과 연결방법에 의해 크게 좌우된다. 만약 현재 신경망 모델이 언더피팅을 겪고 있다고 생각되면 이 캐퍼시티를 점검해봐야 한다.
You can increase the capacity of a network either by making it wider (more units to existing layers) or by making it deeper (adding more layers). Wider networks have an easier time learning more linear relationships, while deeper networks prefer more nonlinear ones. Which is better just depends on the dataset.
신경망의 캐퍼시티를 늘리려면 범위를 옆으로 확장(make it Wider)하거나 레이어 층수를 늘려야 한다 (Deeper.).
범위를 옆으로 늘리는 방법은 선형적 데이터셋에 적합한 방법이고 레이어를 늘려 심층학습을 하는 경우는 비선형 데이터셋에 적합하다. 이것은 데이터셋에 따라 변경해주는 것이 좋다.
#아래 파이썬 코드
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(1),
])
wider = keras.Sequential([
layers.Dense(32, activation='relu'),
layers.Dense(1),
])
deeper = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1),
])
You'll explore how the capacity of a network can affect its performance in the exercise.
신경망의 캐퍼시티가 어떻게 모델 성능에 영향을 주는지 알게될 것이다.
Early Stopping
We mentioned that when a model is too eagerly learning noise, the validation loss may start to increase during training. To prevent this, we can simply stop the training whenever it seems the validation loss isn't decreasing anymore. Interrupting the training this way is called early stopping.
어느 모델이 노이즈를 너무 많이 학습하게 되면 밸리데이션 손실함수 값이 어느 시점부터 증가하게 된다고 설명했다.
이것을방지하려면 우리는 단순히 그 어느 시점에 트레이닝을 멈추면 되지 않을까? 이것을 early stopping 학습 조기 종료 라고 한다.
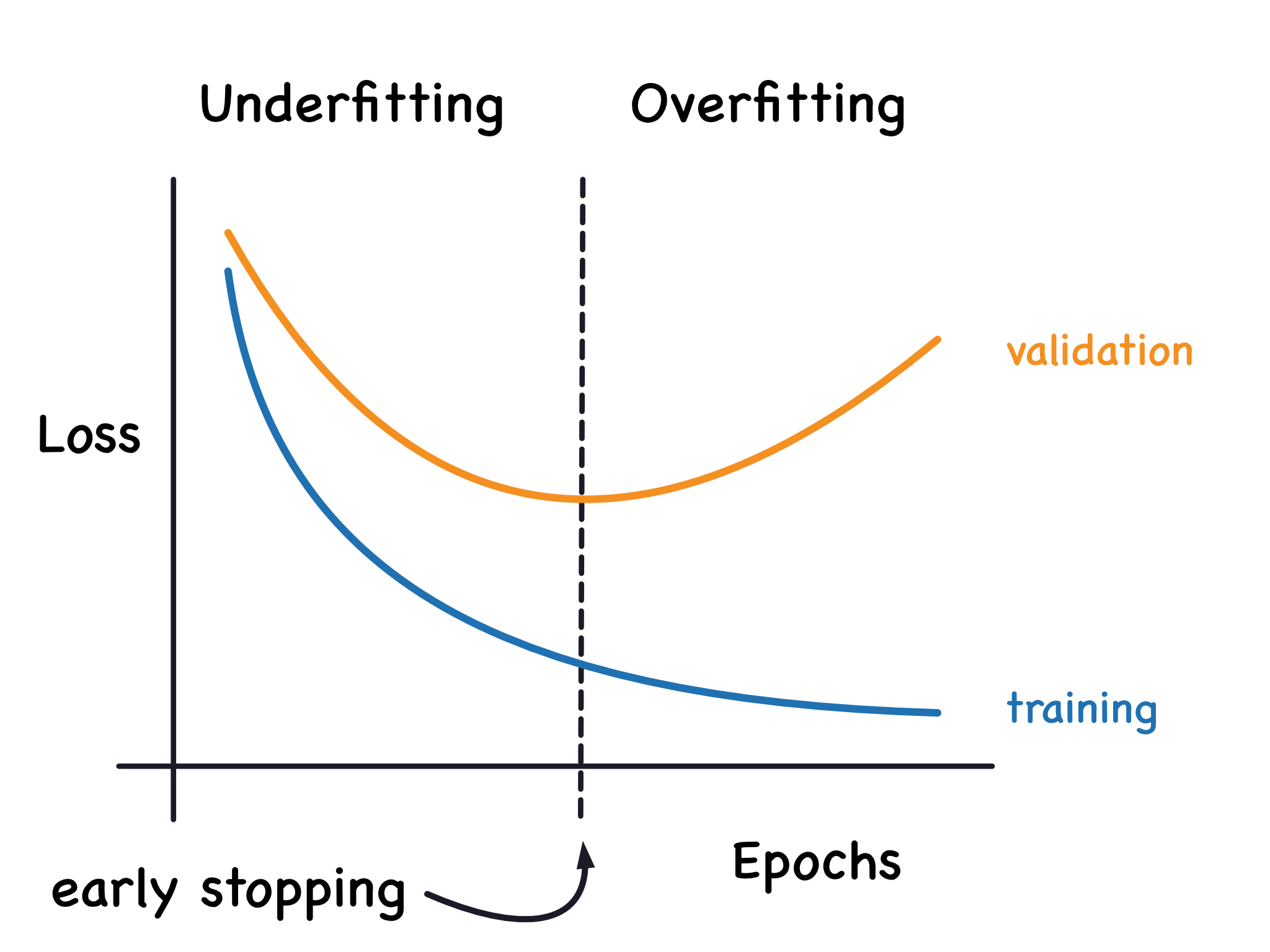
A graph of the learning curves with early stopping at the minimum validation loss, underfitting to the left of it and overfitting to the right.
validation loss의 변곡점에서 early stopping을 하면 최적이다. 이시점을 기준으로 오른쪽은 오버 피팅, 왼쪽은 언더피팅이 된다.
Once we detect that the validation loss is starting to rise again, we can reset the weights back to where the minimum occured. This ensures that the model won't continue to learn noise and overfit the data.
밸리데이션 로스가 다시 상승한다는 것을 감지하면 모델 가중치를 이전( 벨리데이션 로스가 낮았던)으로 되돌리면 되고 이렇게 해서 최저점을 찾을 수 있다.
이렇게 하면 모델이 노이즈를 계속학습해서 오버피팅 되는 것을 막을 수 있다.
Training with early stopping also means we're in less danger of stopping the training too early, before the network has finished learning signal. So besides preventing overfitting from training too long, early stopping can also prevent underfitting from not training long enough. Just set your training epochs to some large number (more than you'll need), and early stopping will take care of the rest.
물론 early stopping을 하면서 너무 조기에 학습이 중단되는 것도 막아야 한다.
가장 손쇠운 방법은 트레이닝 에포크를 크게 잡고 early stopping 시점을 찾는 것이다.
Adding Early Stopping
In Keras, we include early stopping in our training through a callback. A callback is just a function you want run every so often while the network trains. The early stopping callback will run after every epoch. (Keras has a variety of useful callbacks pre-defined, but you can define your own, too.)
Keras에서는 early stopping 을 callback 함수로 구현 가능한데, 이 함수는 신경망이 트레이닝을 하는 동안 에포크마다 호출되는 함수이다.
Keras는 다양한 사전 정의된 callback 함수를 가지고 있고 자신만의 callback 함수를 정의할 수도 있다.
#아래 코딩
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=20, # how many epochs to wait before stopping
restore_best_weights=True,
)
These parameters say: "If there hasn't been at least an improvement of 0.001 in the validation loss over the previous 20 epochs, then stop the training and keep the best model you found." It can sometimes be hard to tell if the validation loss is rising due to overfitting or just due to random batch variation. The parameters allow us to set some allowances around when to stop.
이 파라미터들은 앞서 20 에포크 동안 0.001 이상의 밸리데이션 로스가 개선되지 않았다면 (낮아지지 않았다면) 트레이닝을 멈추고 모델 피팅을 완료한다는 의미다. 물론 때로는 오버피팅으로 인해 벨리데이션 로스가 상승하거나 랜덤 배치에 따른 이유가 발생할 수도 있지만 여기서는 다루지 않겠다.
이 파라미터는 아무튼 어떤 Allowance (허용치)에 대해 이 기준에 들어가면 early stop 해야 한다는 것을 말하고 있다
As we'll see in our example, we'll pass this callback to the fit method along with the loss and optimizer.
...(생략)...
#코딩
from tensorflow import keras
from tensorflow.keras import layers, callbacks
early_stopping = callbacks.EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=20, # how many epochs to wait before stopping
restore_best_weights=True,
)
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)
After defining the callback, add it as an argument in fit (you can have several, so put it in a list). Choose a large number of epochs when using early stopping, more than you'll need.
callback 을 정의하고나서 이것을 fit의 인자(argument)로 전달해야 한다.
epoch 에포크를 선정할때는 큰 숫자를 골라라.(앞에 설명했듯이...)
#코딩
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=500,
callbacks=[early_stopping], # put your callbacks in a list
verbose=0, # turn off training log
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
print("Minimum validation loss: {}".format(history_df['val_loss'].min()))
#history는 모델명인동시에 모델에 붙는 메소드중 하나로 history값을 보여줌. --> history.history를 DataFrame으로 변경한 뒤 이걸 history_df 라는 변수에 넣음.
#데이터프레임.loc() 는 여러 rows나 columns를 라벨로 접근하는 방법. 아래 예시참조.
>DataFrame.loc['row1', 'column1']
>DataFrame.loc[['row2', 'row3'],['column1', 'columns2']]
>DataFrame.loc[조건문]
And sure enough, Keras stopped the training well before the full 500 epochs!
Keras가 500 에포크 가기전에 멈출 수 있는지 잘 확인.